Meta-Reinforcement Learning without Sacrifices
Abstract. The goal of meta-reinforcement learning (meta-RL) is to build agents that can quickly learn new tasks by leveraging prior experience on related tasks. Learning a new task often requires both exploring to gather task-relevant information and exploiting this information to solve the task. In principle, optimal exploration and exploitation can be learned end-to-end by simply maximizing task performance. However, such meta-RL approaches struggle with local optima due to a chicken-and-egg problem: learning to explore requires good exploitation to gauge the exploration's utility, but learning to exploit requires information gathered via exploration. Optimizing separate objectives for exploration and exploitation can avoid this problem, but prior meta-RL exploration objectives yield suboptimal policies that gather information irrelevant to the task. We alleviate both concerns by constructing an exploitation objective that automatically identifies task-relevant information and an exploration objective to recover only this information. This avoids local optima in end-to-end training, without sacrificing optimal exploration. Empirically, DREAM substantially outperforms existing approaches on complex meta-RL problems, such as sparse-reward 3D visual navigation.
Qualitative Analysis of DREAM
We provide visualizations and analysis of the policies learned by DREAM and other approaches below.
Distracting Bus

Examples of different problems and goals. In different problems, the colored buses in the corners change positions to be one of the 4! permutations. In different episodes, the goal location changes to one of the four corners.
In the distracting bus task, the agent must go to the goal location (green square), which is randomly placed in one of the four corners, in as few timesteps as possible. In different problems, the destinations of the buses is randomized to different permutations. See the two examples above.
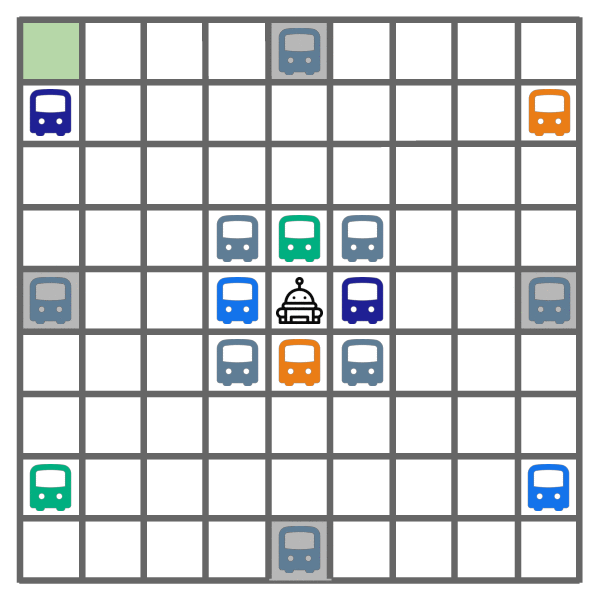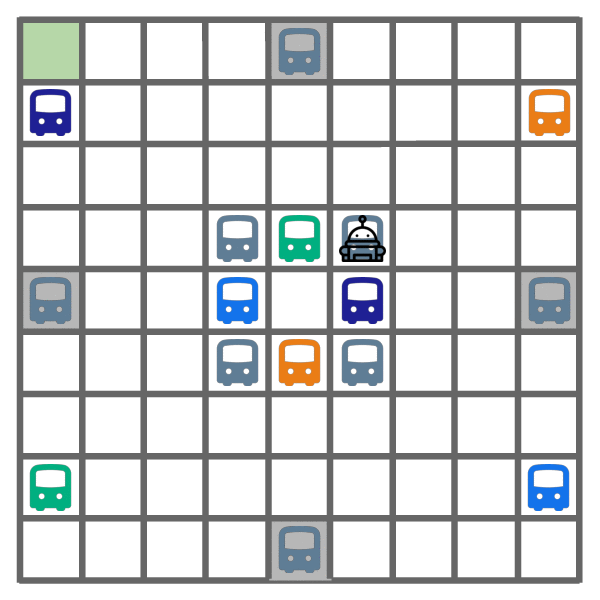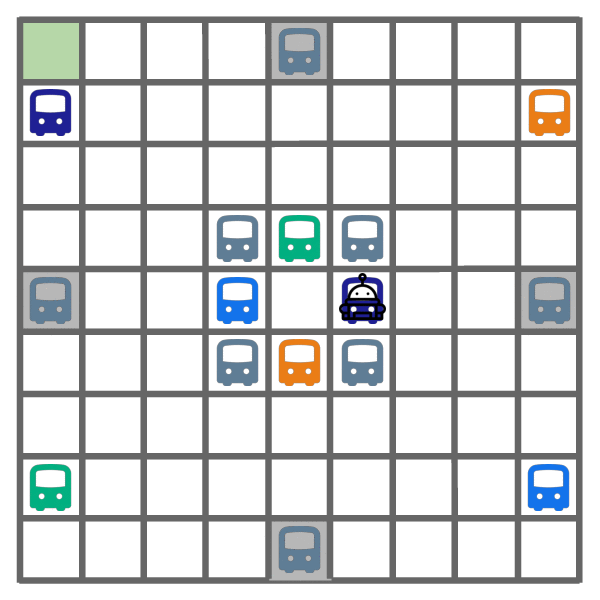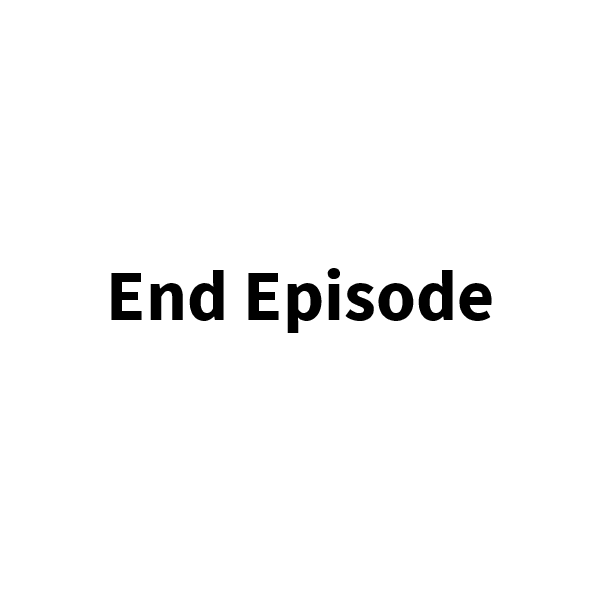
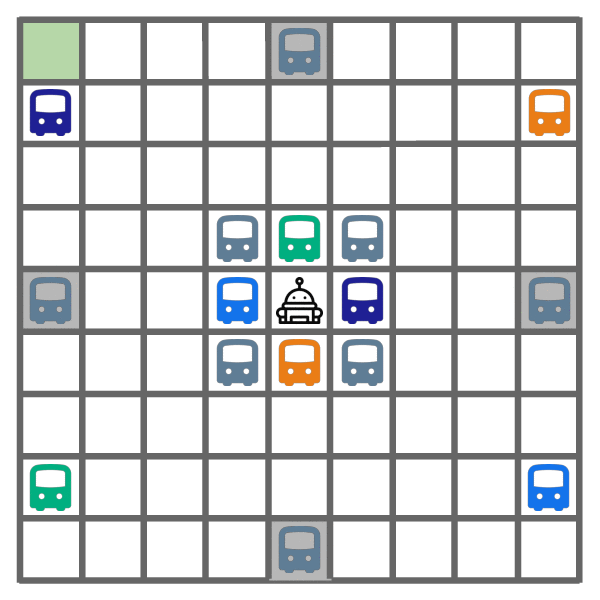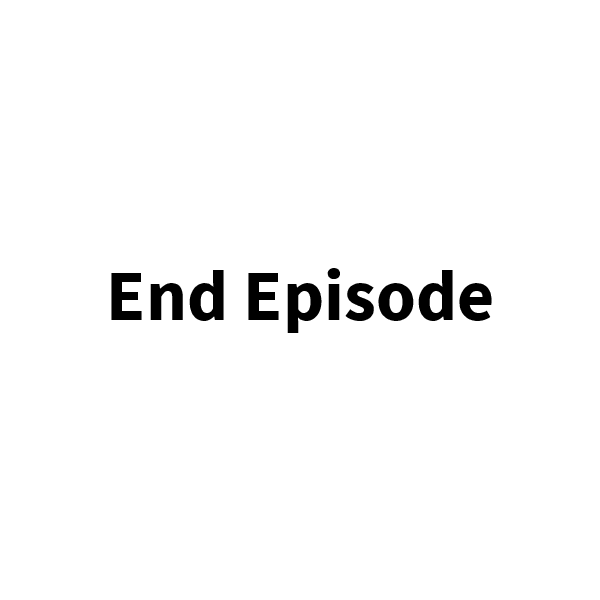
Exploration learned by DREAM.

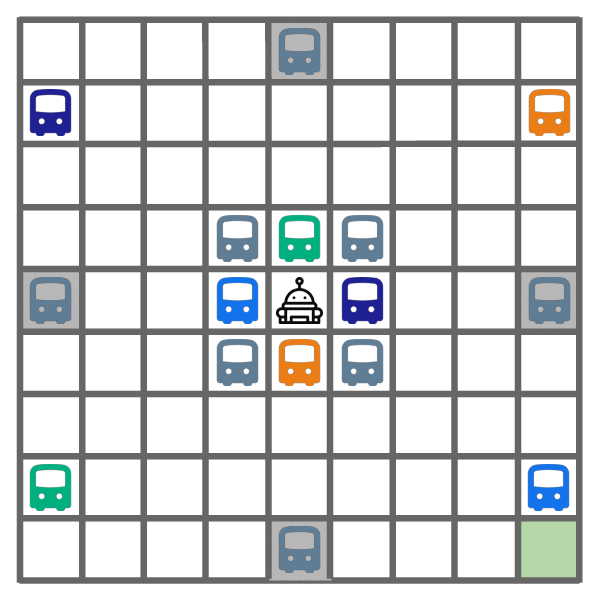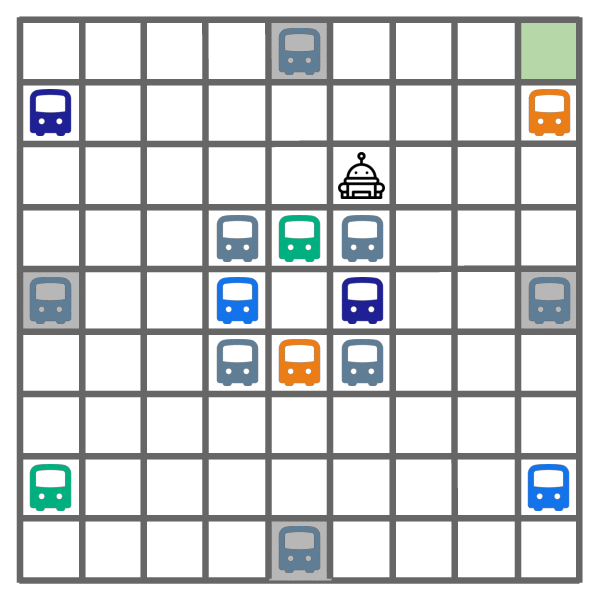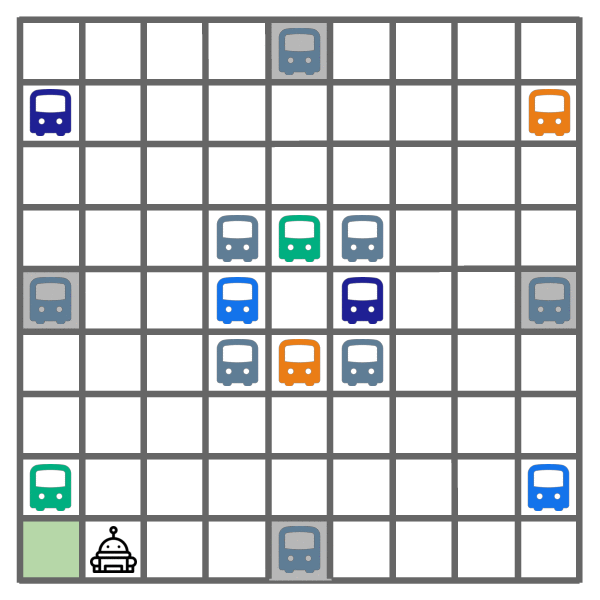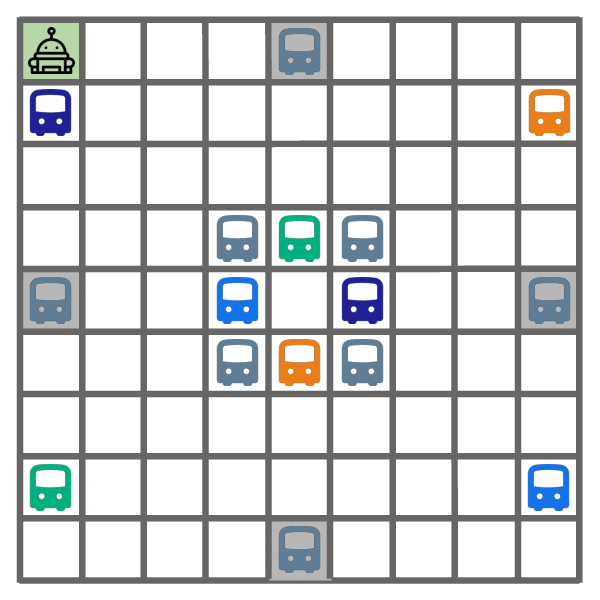
Exploitation learned by DREAM.
As shown above, DREAM learns to optimally explore (left) by visiting all of the helpful (colored) buses, while ignoring all the unhelpful (gray) buses. During exploitation episodes (right), this allows it to ride the bus that leads closest to the goal, which yields optimal returns.
In contrast, as shown below, both IMPORT and E-RL2 get stuck in a local optimum due to the chicken-and-egg problem, where they learn not to explore at all (left), opting to immediately end the exploration episode. This yields suboptimal exploitation behavior (right), which walks to the goal, since the bus destinations are not learned during exploration.
Exploration learned by E-RL2 and IMPORT.
Exploitation learned by E-RL2 and IMPORT.
Cooking
Examples of different problems and goals. In different problems, the three fridges on the right are different colors, indicating different ingredients. In different episodes, the goal (recipe) changes to be placing two ingredients in the pot in the correct order.
In the cooking task, the agent must place two ingredients in the pot in the order specified by the recipe (goal). The (color-coded) ingredients in the fridges change in different problems. See the examples above. The agent receives positive reward for each step of: 1) picking up the correct first ingredient; 2) placing it in the pot; 3) picking up the correct second ingredient; 4) placing it in the pot. The agent receives a per timestep negative reward and also a large negative reward for picking up the wrong ingredient (as it goes to waste).
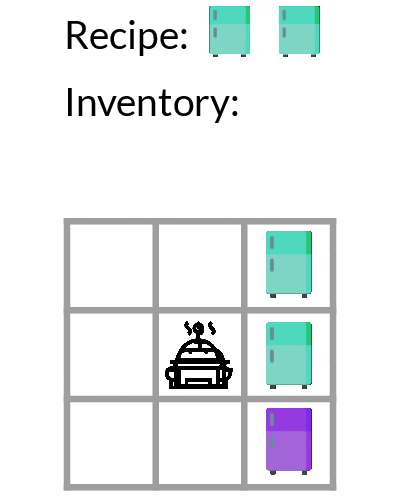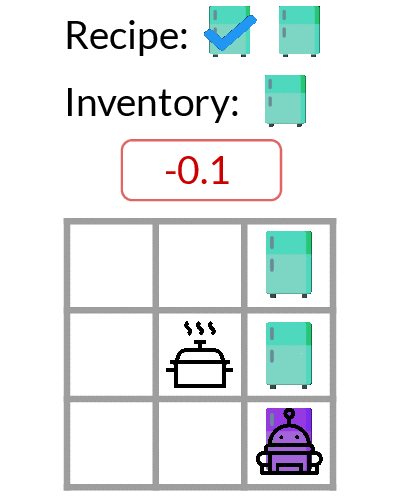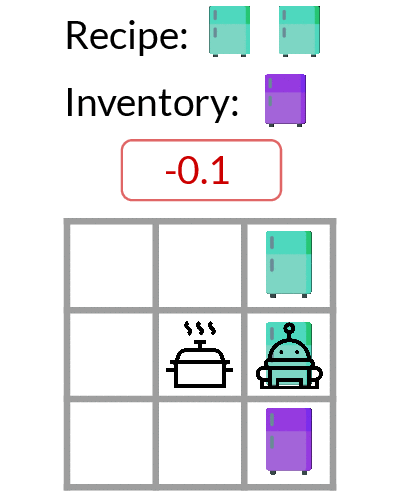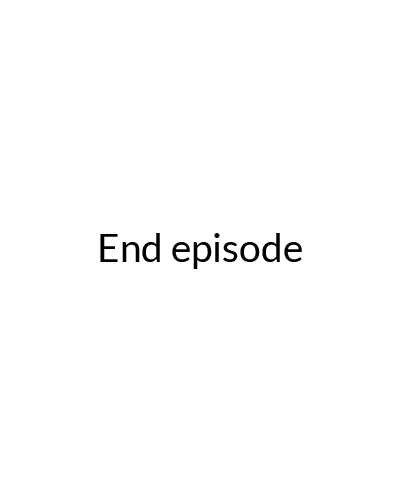
Exploration learned by DREAM.

Exploitation learned by DREAM.
As shown above, DREAM learns to optimally explore by picking up the ingredients from each of the fridges one-by-one, which allows it to learn where each ingredient is located (left). Then during exploitation episodes (right), it then achieve optimal returns by directly retrieving the ingredients specified by the recipe.
In contrast, as shown below, E-RL2 and IMPORT, get stuck in a local optimum due to the chicken-and-egg problem, where they suboptimally explore by only visiting a single fridge (left). Consequently, during exploitation episodes (right), they don't know where the purple ingredient is located, so they wastefully accidentally grab an extra green ingredient from the top-right fridge, which incurs high negative reward.
Exploration learned by E-RL2 and IMPORT.
Exploitation learned by E-RL2 and IMPORT.
Sparse-Reward 3D Visual Navigation

Sign reads green.

Sign reads red.
The sparse-reward 3D visual navigation task evalutes agents' ability to scale to problems with high-dimensional visual observations and sophisticated exploration challenges, pictured above. We've made the benchmark from Kamienny et al., 2020 harder by including a visual sign and more objects. Each episode contains a goal to collect either a block or key. The agent starts episodes on the far side of the barrier, and must walk around the barrier to read the sign (highlighted in yellow), which in the three versions of the problem, specify going to the green, red, or blue (not shown) version of the object. The agent receives 80x60 RGB images as observations and can turn left or right, or move forward. Going to the correct (correct color and shape) object gives reward +1 and going to the wrong object gives reward -1. Otherwise, the agent receives 0 reward.
DREAM learns near-optimal exploration and exploitation behaviors on this task, which are pictured below. On the left, DREAM spends the exploration episode walking around the barrier to read the sign, which says blue. On the right, during an exploitation episode, DREAM receives the goal to collect the key. Since DREAM already read that the sign said blue during the exploration episode, it collects the blue key.

Exploration learned by DREAM.

Exploitation learned by DREAM (collect the key).
Comparisons. Broadly, prior meta-RL approaches fall into two main groups: (i) end-to-end approaches, where exploration and exploitation are optimized end-to-end based on exploitation rewards, and (ii) decoupled approaches, where exploration and exploitation are optimized with separate objectives. We compare DREAM with state-of-the-art approaches from both categories. In the end-to-end category, we compare with:
- E-RL2 (Stadie et al., 2018), the canonical end-to-end approach, which learns a recurrent policy conditioned on the entire sequence of past state and reward observations, modified to better learn exploration.
- VariBAD (Zintgraf et al., 2019), which additionally adds auxiliary loss functions to the hidden state of the recurrent policy to predict the rewards and dynamics of the current problem. This can be viewed as learning the belief state (Kaelbling et al., 1998), a sufficient summary of all of its past observations.
- IMPORT (Kamienny et al., 2020), which additionally leverages the problem identifier to help learn exploitation behaviors.
- PEARL-UB, an upperbound on PEARL (Rakelly et al., 2016). We analytically compute the expected rewards achieved by the optimal problem-specific policy that explores with Thompson sampling (Thompson, 1933) using the true posterior distribution over problems.
Quantitative results. Below, we plot the returns achieved by all approaches. In contrast to DREAM, which achieves near-optimal returns, we find that the end-to-end approaches get stuck in local optima, indicative of the coupling problem. They never read the sign, and consequently avoid all objects, in fear of receiving negative reward for going to the wrong object. This achieves 0 reward.
On the other hand, while existing approaches in the decoupled category avoid the coupling problem, optimizing their objectives does not lead to the optimal exploration policy. For example, Thompson sampling approaches (PEARL-UB) do not achieve optimal reward, even with the optimal problem-specific exploitation policy and access to the true posterior distribution over problems. Recall that Thompson sampling explores by sampling a problem from the posterior distribution and following the exploitation policy for that problem. Since the optimal exploitation policy directly goes to the correct object, and never reads the sign, Thompson sampling never reads the sign during exploration.
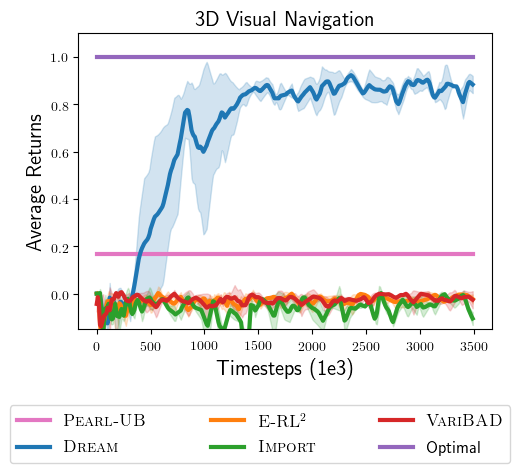
Only DREAM reads the sign and solves the task.
Additional Experiments
In the experiments, we evaluated DREAM to answer the following questions:
- Can DREAM efficiently explore to discover only the task-relevant information in the face of distractions?
- Can DREAM leverage informative objects to aid exploration?
- Can DREAM learn exploration and exploitation behaviors that generalize to unseen problems?
- Can DREAM scale to challenging exploration problems with high-dimensional states and sparse rewards?
Source Code
Check out the code for DREAM and the benchmarks we evaluate on at GitHub!
Paper and BibTeX
|
Acknowledgements
This website is adapted from this website, which was in turn adapted from this website. Feel free to use this website as a template for your own projects by referencing this!
The grid world animations were made by Arkira Chantaratananond.
Icons used in some of the above figures were made by Freepik, ThoseIcons, dDara, Pixel perfect, ThoseIcons, mynamepong, Icongeek26, and Vitaly Gorbachev from flaticon.com.